Charles Dickens's Our Mutual Friend
Clarendon Edition
Navigation
- Home
- General Introduction
- Project Description
- Textual Witnesses
- Collations
- Illustrations
- Links
- The Clarendon Dickens
- Publications
- Contacts
The Mechanics of Digitising Text
One of the major aims of the project is to produce digital images of the various editions of Our Mutual Friend and Word documents of each chapter of each edition. Digitising the editions involves working through a number of processes using the textual recognition application, OmniPage Pro 12.0. This is used to scan each chapter, perform textual recognition and to then convert the scanned images to PDF files and text files. These processes are described below.
Firstly, the editions are scanned one chapter at a time. This is done using a Hewlett Packard Scanjet 6300C. In order to produce the optimum image the settings are adjusted to brightness 43% and contrast 56% and the text is scanned in colour. Where possible the original texts are scanned directly. This is done for the First Monthly Edition in parts, the First 2 Volume Edition, the Cheap Edition, the Dickens Edition and the Tauchnitz Monthly Parts (Part 1, Chapters 1-4 & Part 3, Chapters 8-10). If the original edition can not be accessed for this purpose, print-outs of the microfilm copy of the original are scanned, as initial efforts to scan directly from the microfilm produced inadequate images. This is done for the Tauchnitz Edition in Four Books, the Harpers New Monthly Magazine, the Library edition and the Diamond Edition.
When a chapter has been scanned, the images can be viewed on OmniPage Pro 12.0 and saved as an OmniPage Pro file (see figure 1).
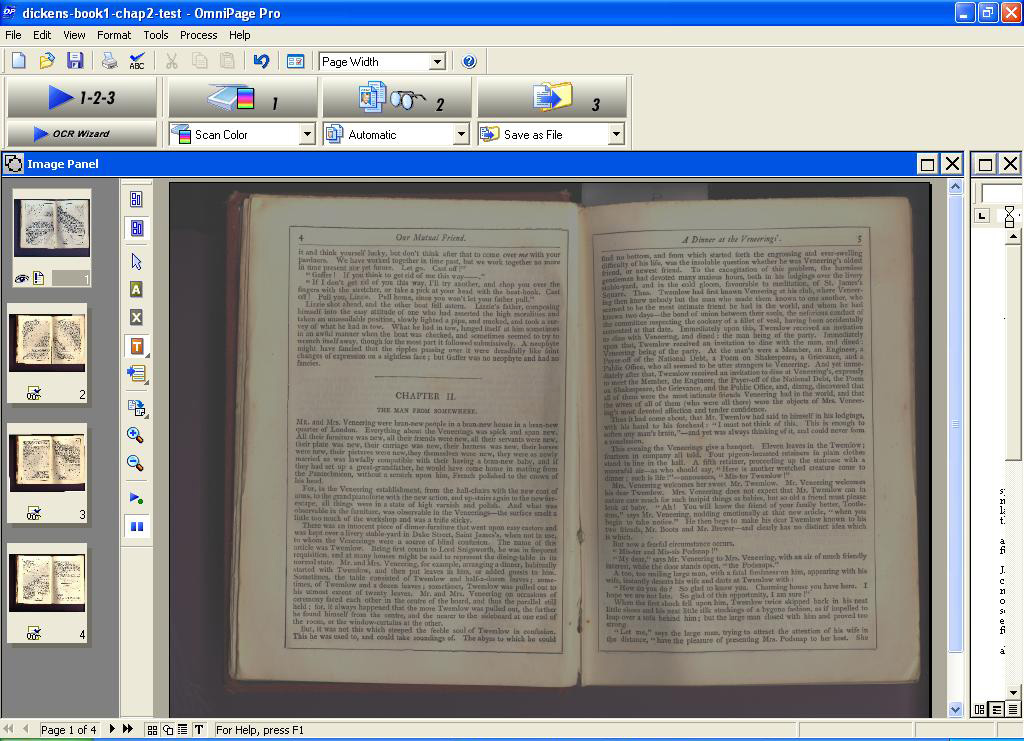
Figure 1
Before converting these images to a Word document, Optical Character Recognition (OCR) must be performed. The OmniPage Pro application highlights any words that have not been recognised and permits changes to be made to the text file being created. To perform OCR each image of a double-page must be verified individually. In order to do this the text must be isolated from the rest of the image. This is done by drawing a text zone around it as shown in figure 2, below.
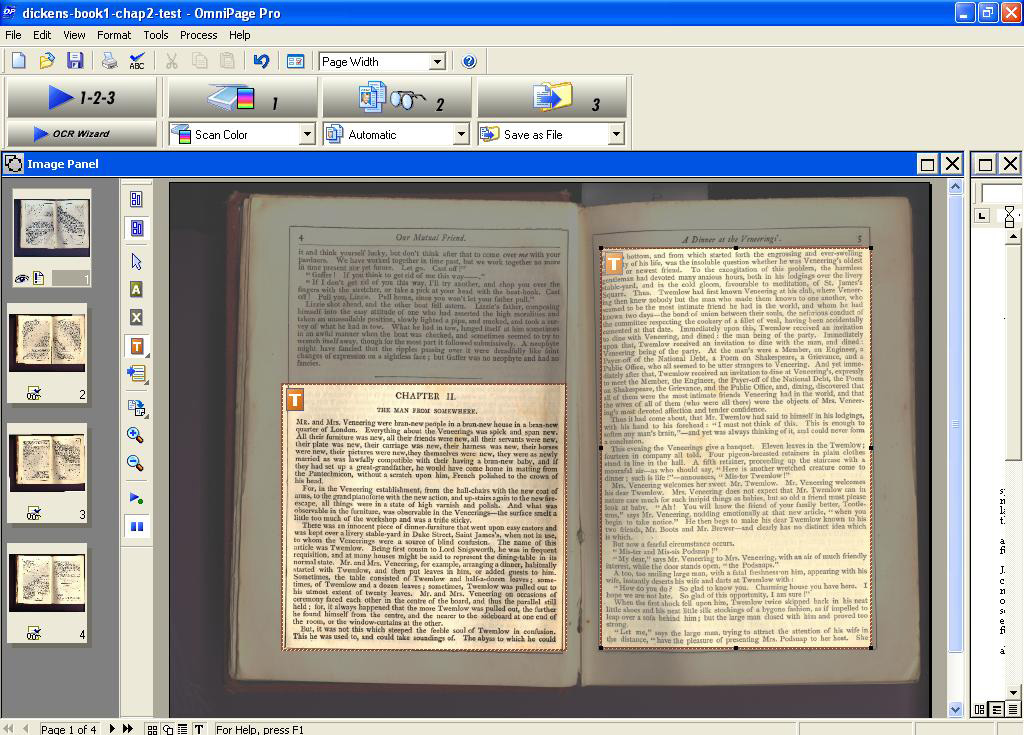
Figure 2
For the cheap edition, in which text is laid out in two columns per page, text boxes must be drawn around each column of text, as shown in figure 2b.
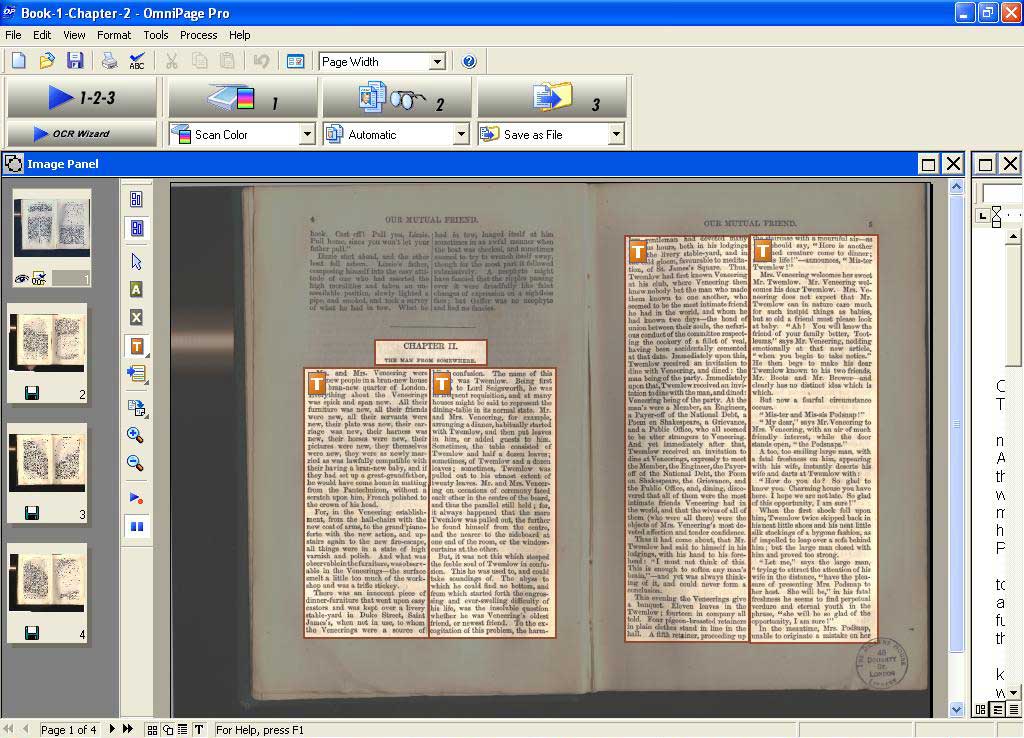
Figure 2b
By right-clicking inside the selected zone, a drop down menu appears. Selecting ‘Zone Type’ and then ‘Text’ prepares this image for textual recognition. The ‘Step 2’ or ‘Perform OCR’ icon on the OmniPage Pro Toolbox toolbar is then selected. The selected area of text is checked by the application’s spellchecker and any words not recognised by the programme and any grammatical errors are highlighted. This allows a manual check of the application’s interpretation of the text against the original image (see figure 3).
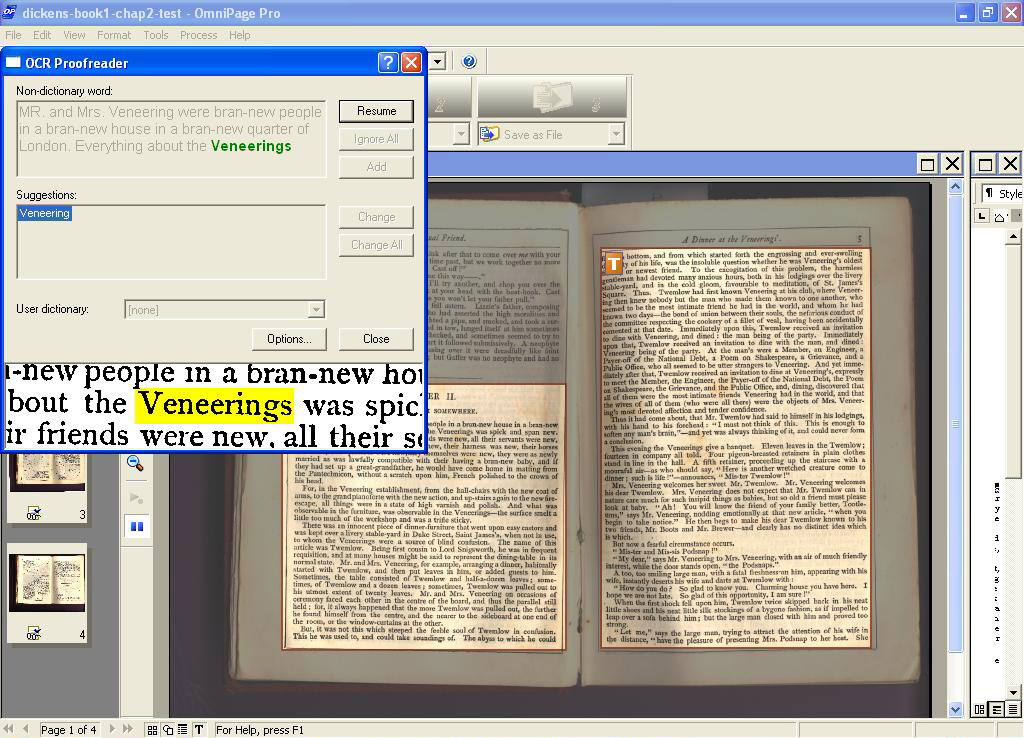
Figure 3
When this process is complete, the file can be converted to a Word document by selecting ‘Save As’ and saving it as a Microsoft Word 2000.XP file. When saving the document the formatting of ‘Retain Fonts and Paragraphs’ is selected in order to retain as much as the original layout of the text as possible.
To convert the original scanned images into graphic images in Adobe instead of text documents, a zone is drawn around every double-page image in the OmniPage Pro file. Selecting ‘Zone Type’ and then ‘Graphic’ in the drop-down menu, brought up by right clicking within the zone, prepares this image for conversion to a PDF file (see figure 4).
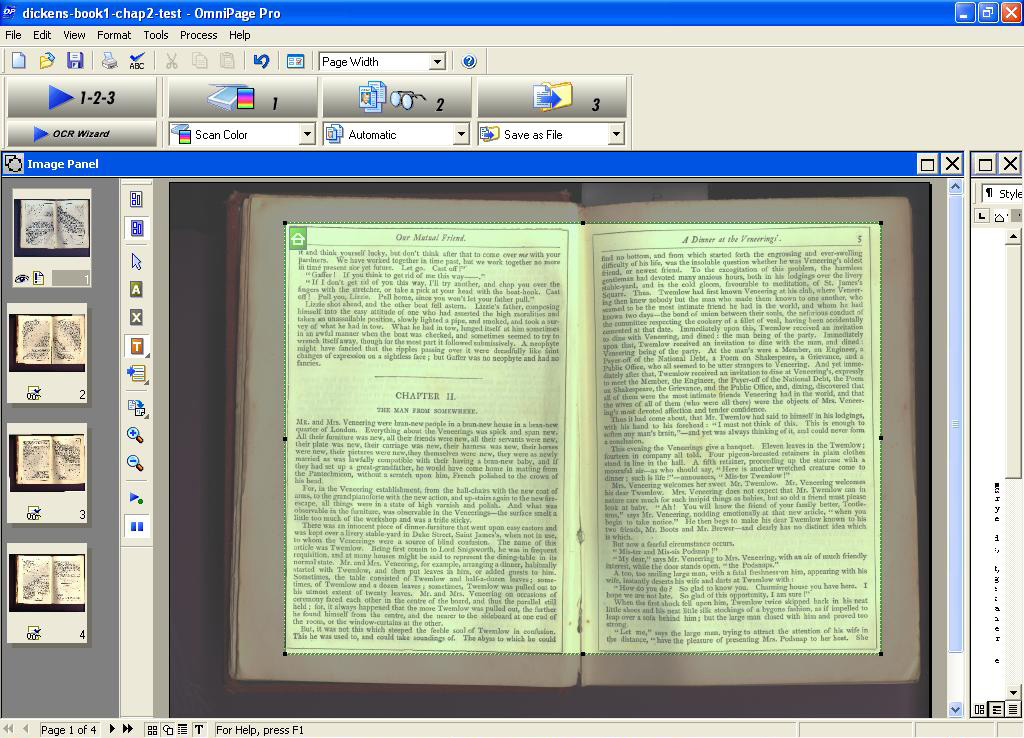
Figure 4
By selecting ‘Save File as’ and saving it as a ‘PDF’ file, the scanned images stored in OmniPage Pro will be converted into graphic images in Adobe files. These images, for example figure 5, below, are uploaded to this website and are available for viewing in the Textual Witnesses section.
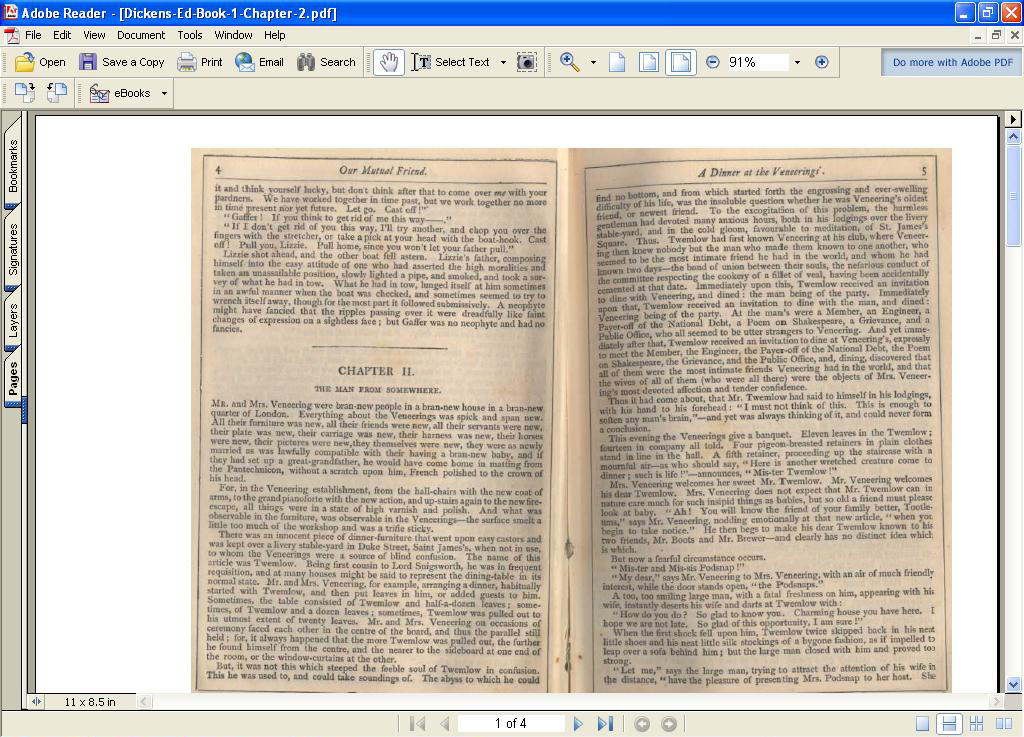
Figure 5
The Word files, however, require further formatting and confirmation of accuracy before they are complete. In spite of the OCR process and the effort to retain formatting when converting the scanned images to text, some errors and irregularities are introduced. The Word files are therefore subject to three further processes before they are confirmed to be accurate versions of the text appearing the relevant edition of Our Mutual Friend. Firstly, each Word document is formatted in a regular font (Times New Roman, 12 pt) for ease of reference and the layout of paragraphs and direct speech is checked. Then each Word file is examined against the original chapter. This is necessary because the OCR programme, in some instances, fails to recognise certain combinations of letters (for example, ‘He’ is often interpreted as ‘lie’), misinterprets shading or marks on the original as letters or punctuation and does not always recognise spacing after punctuation marks. While the aim is to produce a collation of the original text retaining the irregularities of the specific editions, certain standards (such as the spacing after full-stops and commas) are applied to the Word document. When the document has been fully proofread and all inaccuracies have been corrected on the Word file, this version of the text is uploaded and made available online.
This process of digitising the text is ongoing. Ultimately, a graphic image and a Word document of each chapter in each edition will be available on this site.