

Choosing a File Name
File naming is a vital first step for those beginning to digitise. This document examines planning and using an effective file naming system when managing digital files. This paper highlights the advantages of using the 8.3 convention and looks at some options when naming derivative, surrogate files.
'8.3 filenames have at most eight characters, optionally followed by a period . and a filename extension of at usually three characters.'
Introduction
When you capture your very first digital file, you need to decide how and what to name it. File naming is an issue that should be considered from the very outset of a digitisation project, and the file naming system you establish should be outlined within the project specifications.
Appropriate file naming for your project may seem obvious, especially if the collection is a small one or if each file is to be given a consecutive number, but careful consideration needs to be given when deciding how to name or number files in any digital collection. A useful file naming system will not only ensure consistency, but will also form an integral part of the retrieval process.
For small collections, file naming may only involve giving each document a sequential number or a descriptive name. However, no matter how simple the chosen filenames may seem, there are some useful guidelines to bear in mind before diving in.
File naming standards
Both Microsoft Windows (95 onwards) and Apple Macintosh operating systems now allow long filenames. However, if a file is to be truly compatible across platforms, it should be named according to the 8.3 Convention which limits names to eight characters, followed by a three-character extension (such as 12345678.txt). This is particularly important when burning files to CD-R or DVD-R, as the ISO 9660 file naming standard uses 8.3 to assure interoperability across all platforms.
Filenames should avoid punctuation characters in their names altogether. This is because some characters such as \ / : * ? " < > | are reserved for use by the operating system itself. Spaces should be avoided or replaced with hyphens or underscores particularly with files destined for the Web.
Descriptive filenames
Filenames can be neatly divided between those that are 'descriptive' and those that are 'non-descriptive'. A descriptive filename is made up of actual words, abbreviations or numbers that bear some relation to the content, name or accession number of the asset itself; whereas a non-descriptive filename is likely to consist of numbers, or a combination of numbers and characters, that have no significant 'human' meaning.
Descriptive file naming systems tend to suit smaller collections where it is easy for users to visually browse through a set of descriptively named folders and files. For example, a collection of 20,000 film posters might be divided up first by decade (giving a set of folders named 1920, 1930, 1940, etc.), then by the film title's initial letter (folders a, b, c, etc.), followed by a unique number (001, 002, etc.). So a filename for a poster of Gone with the Wind might be: 1930g001.tif.
Diagram 1. Descriptive filename in a folder structure
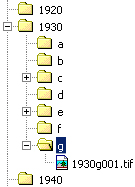
This particular example also highlights a potential problem, or rather it emphasises the need for proper planning: by choosing 001, 002, 003, etc, rather than 1, 2, 3, or 01, 02, 03, etc, the system used here allows for up to 1,000 individual filenames (000 - 999) in each section - but what happens if one decade has more than a thousand film titles starting with the same letter?
Of course there are many possible solutions, but it serves to show that more than a little thought needs to go into the structure of the filename - it would be easy enough to add an extra zero (1930g0001.tif), but that would go beyond the recommended eight-character limit. With careful planning, descriptive 8.3 filenames can contain enough information to provide some indication as to the content of the file. 1930vf01.tif (vf folder for films directed by Victor Fleming) or 1939gwtw.tif (abbreviated film titles, one folder per year) or39mgm-01.tif (films produced by MGM per year).
However, this reveals one of the problems with descriptive naming: it can be very hard to create a descriptive name within eight characters that makes sense. Strange combinations of letters and numbers may have a meaning to those that created them, but if that meaning is unclear to others and requires a key to be understood, then the whole point of the filenames being descriptive is lost.
Another option would be to keep the same folder structure and simply name each file001.tif, 002.tif, etc. (or 00000001.tif to allow for more filenames). This might be a suitable way to organise a collection of books, naming each file after its page number. This sort of system can work well, but requires a descriptive folder structure it can rely on to help identify individual files, as many of the filenames will not be unique (i.e. files from several different folders would be named 001.tif).
Diagram 2. Naming each file after page number
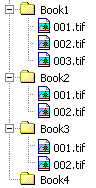
The filenames in such a system are clearly not descriptive in themselves, but are made so by their place in the folder structure.
The alternative would be to assign descriptive filenames that are unique. This would help identify the content of the files even if they were removed from the folder system. The disadvantage here, and indeed in any descriptive system, is that each filename needs to be assigned manually, which increases the likelihood of mistakes or the same name being given to more than one file.
Diagram 3. Giving each file a unique name
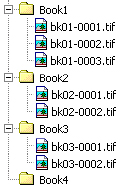
Non-descriptive filenames
Non-descriptive filenames are more suited to larger collections or those using a more sophisticated digital asset management system (DAMS), DAMS normally create the files internally and then generate unique filenames automatically. These might be randomly generated or could be consecutively assigned numbers. Either way, once digitisation has been completed, each file in the collection has a basically meaningless number as its filename, but each one would be guaranteed to be unique.
A system that uses such filenames is obviously not going to be of much use from a search and retrieval point of view unless there is a DAMS in place to connect the numbers with their indexing metadata. This is one of the reasons why non-descriptive filenames suit larger collections - a collection that is too big to be browsed in any sensible fashion relies on a database to locate the files, making descriptive filenames unnecessary.
The larger the collection, the greater the chance of mistakes (incorrect or duplicate filenames), so a simple and reliable consecutive numbering system is often thought to be the best way to ensure each filename is unique. Use of the 8.3 naming standard still allows for up to 99,999,999 unique filenames, and if some numbers are replaced with letters this system should be able to cover just about any size of collection.
Unlike descriptive filenames, which can help identify files independent of their database, a consecutive numbering system confines the files to being identified only by the metadata in the database that holds them. Safeguarding the DAMS is therefore of as much importance to a digital preservation strategy as protecting the digital objects themselves - without the DAMS, randomly-named files mayl be useless.
Surrogate files
The naming system should also take into account the creation of surrogate files - those files made from the archive for delivery (e.g. for the Web or print). For a still image collection a typical 'image pack' for delivery on the Web might consist of several differently sized JPEGs: a thumbnail, reference image, full screen image, and a full size JPEG, all created from the original master TIFF.
If the master archive files use the 8.3 naming structure, it is of less importance for the surrogate files to do so: after all, they are derived from the master archive, which is where preservation is really important. Longer filenames can be used for delivery files if necessary.
Using 1930g001.tif as an example, one choice would be to add suffixes for each size of JPEG, e.g. -tn for thumbnail; -rf for reference; -sc for full screen; -fs for full-size.
Diagram 4. Surrogate files with unique filenames
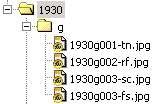
The other option, which would keep the files in 8.3, would be to create a series of folders for each size and use the same filename in each:
Diagram 5. Surrogate files organised according to file size
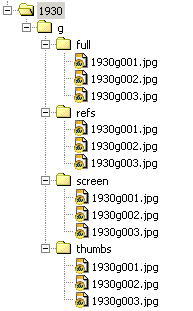
As previously mentioned, once removed from the folder structure, files with identical names may cause problems. However, in this case each file is referring to a version of the same digital object and it is easy enough to work out which is which by file size alone.
There is no real right or wrong answer for surrogate file naming: some projects may decide that having unique identifiers is more important than staying within eight-characters. Of course, there is no reason why surrogate filenames cannot be both unique and within 8.3: either by abbreviating the original master filename and adding a relevant suffix (e.g. 39g001tn.jpg), or by creating random filenames for each surrogate. As long as they can be linked back to the original master file (i.e. using the metadata in a DAMS), the actual filename for surrogate images need not be descriptive.
Files being created for delivery on the Web should avoid the use of upper case characters, as some operating systems such as Unix are case-sensitive. Spaces should also be avoided, as some Web browsers will 'throw away' anything after a space.